
Netflix Software Engineer Phone Screen Questions
29+ questions from real Netflix Software Engineer Phone Screen rounds, reported by candidates who interviewed there.
What does the Netflix Phone Screen round test?
The Netflix phone screen typically lasts 45-60 minutes and evaluates core Software Engineer fundamentals. Candidates should expect 1-2 algorithmic problems, basic system design discussion at senior levels, and questions about relevant experience. The goal is to confirm technical competence before bringing candidates onsite.
Top Topics in This Round
Netflix Software Engineer Phone Screen Questions
Hubspot | Senior Software Engineer | Berlin | Reject
Round 1 - Algorithm round Provided an API key to fetch the data(json) from a url. This data contains the list of partners and their countries and on which dates they...
Online application -> HR contacted -> Asked about Faye Wong's culture and his proudest project. First round in-store interview -> Implement a key-value pair that can expire -> Follow-up question: How
Hubspot - sse2
round 1 : q - given a string s = "aabbaaa", k =2 , find string of length k which occurs in s most no of times. ans - aa round...
Netflix L4 Software Engineer Remote Interview Experience and Questions
**Round 1** * **Recruiter Call (30 min)** * **Technical Phone Screen (60 min):** The problem required implementing a rate limiter that allows specific X requests every Y seconds from a single client.
EPAM | Senior Software Developer | Hyderabad | Dec 2023 [Passed]
Status: IN3, Walmart Global Tech, Bengaluru - 6yrs overall experience Position: Senior Software Developer at EPAM Location: Hyderabad, India Date: Dec, 2023 Round 1: Introduction: Gave a brief introduction about my experiences. Java-Related Questions: JVM, Heap memory,...
Geico | Remote | SDE II | Virtual Onsite Interview
Company: Geico Position: SDE II Salary: $155,000 RSU: None offered Sign On: $15,000 Location: Fully Remote US Status: Offer Virtual Onsite Rounds: Coding Round 1 (30 mins): Similar to: Transform number with duplicate digits into the next highest...
[PS] [Interview #5] Parspec Interview experience
Interviewing for Role Software Architect | Bengaluru | November 2023 Current Stats Status: Lead Engineer at B2B based startup Location: Bengaluru Interview process: Round-1: Exploratory Round a. Phone Interview call with CTO b. Discussion...
Netflix | Phone screen
I recently had a technical interview over the phone with Netflix. Basically the same question: https://leetcode.com/discuss/interview-question/279913/bloomberg-onsite-key-value-store-with-transactions 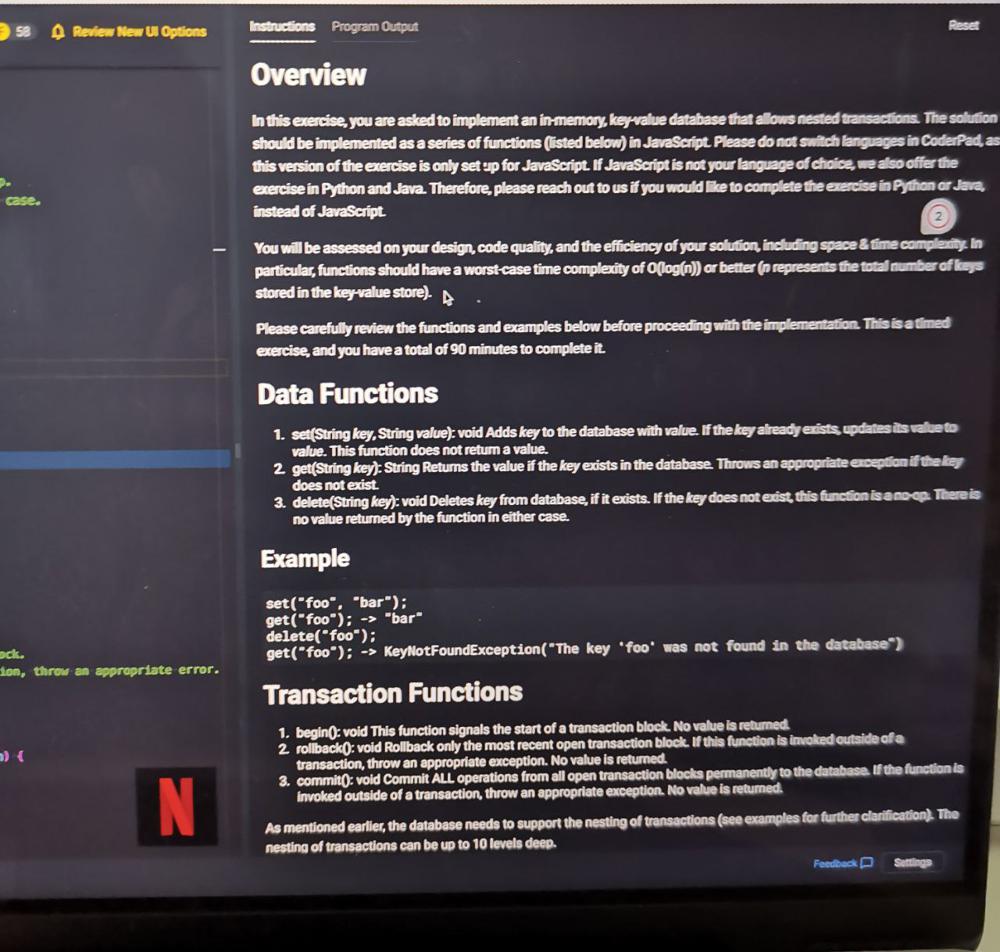 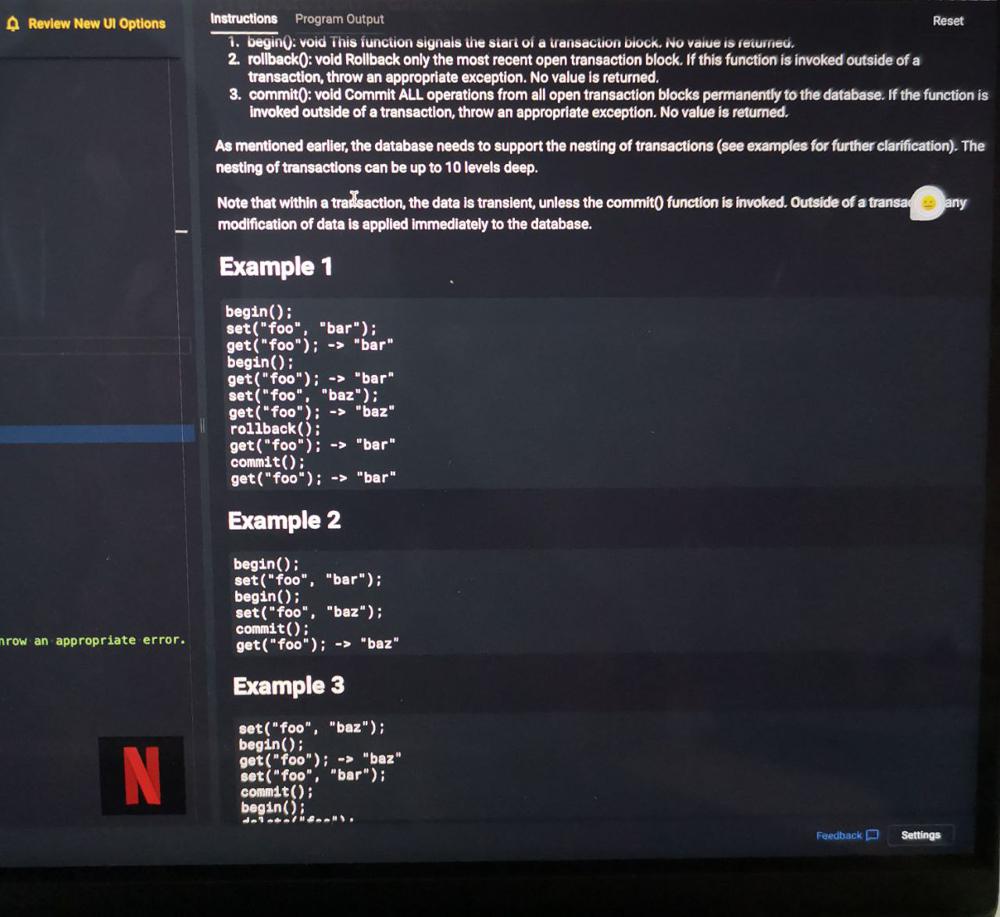 Interviewer wanted me to solve this question using JS. I came up with the map...
Phonepe|SDE-Tools Internship (Oncampus)| June 2022
Hello! this was my experience being interviewed by Phonepe for their SDE-Tools for network infrastructure role . Status: Fresher (Graduating in 2023) | Tier 2 College in India Experience: 6 month internship...
SAP Labs | SSE | Bangalore
Round 1: - Write an efficient function that takes stockPrices and returns the best profit I could have made from one purchase and one sale of one share of SAP stock...
Wayfair Software Engineer Interview
Status: Software Developer with 2 years of full time Experience School: The University of Akron Wayfair Software Engineer Interview I recently went through a Wayfair interview and wanted to contribute the questions...
## Problem Given a set of numbers and arithmetic operations, determine if a target value can be reached. Likely involves expression generation or backtracking. ## Likely LeetCode equivalent No direct match. ## Tags math, backtracking, coding
## Problem Implement a command history system (like a shell undo/redo or browser history) supporting navigation through previous commands. Likely uses two stacks or a deque. ## Likely LeetCode equivalent No direct match. ## Tags stack, design, coding
## Problem Given a list of strings, count the number of pairs `(i, j)` where `i < j` and the two strings share no common characters. ```python def count_disjoint_pairs(words: list[str]) -> int: ... ``` ``` Input: words = ["abc", "de", "fg", "abcd"] Pairs: ("abc","de"): no overlap -> count ("abc","fg"): no overlap -> count ("abc","abcd"): overlap 'a','b','c' -> skip ("de","fg"): no overlap -> count ("de","abcd"): overlap 'd' -> skip ("fg","abcd"): overlap -> skip Output: 3 ``` ## Follow-ups 1. Represent each word as a bitmask of 26 bits (one per letter). How does this make the disjoint check O(1)? 2. With the bitmask approach, what is the overall time complexity? How does it compare to using a set intersection? 3. Can two different words share the same bitmask? Give an example. Does this cause any issue for your algorithm? 4. Extend: count pairs where the two strings share exactly one common character. How does your bitmask approach need to change?
## Problem You are given a list of viewing events for a single user. Each event has a `show_id` and a `timestamp`. A "duplicate" viewing occurs when the same `show_id` appears more than once within a 24-hour window of its first occurrence. Return a deduplicated list preserving only the first occurrence of each show within any 24-hour window. ```python from typing import List, Tuple def deduplicate_viewings(events: List[Tuple[str, int]]) -> List[Tuple[str, int]]: # events: list of (show_id, unix_timestamp_seconds) # return: filtered list in original order pass ``` **Example:** ``` Input: [("S1", 1000), ("S2", 1500), ("S1", 86200), ("S1", 87200)] Output: [("S1", 1000), ("S2", 1500), ("S1", 87200)] # S1 at 86200 is within 86400s of S1 at 1000, so dropped. # S1 at 87200 is outside the window, so kept (new window starts). ``` ## Follow-ups 1. What if events can arrive out of order by timestamp? How does your approach change? 2. How would you scale this to process millions of users' events per day in a streaming pipeline? 3. What if "duplicate" is defined per (show_id, season_number) pair instead of show_id alone? 4. How would you emit a count of dropped duplicates per show alongside the filtered list?
Netflix SWE Phone - Event Logger
## Problem Implement an event logging system that records timestamped events and supports queries such as range lookups or count within a time window. ## Likely LeetCode equivalent No direct match. ## Tags coding, design, hash_table
Netflix SWE Phone - Function Timer
## Problem Implement a wrapper or decorator that measures execution time of functions, possibly with aggregation or reporting of stats. ## Likely LeetCode equivalent No direct match. ## Tags coding, design, oop
## Problem You are building the homepage feed for a streaming platform. Given a list of content items and a user's watch history, return the top `k` items to display. Ranking rules (in priority order): 1. Items the user has NOT watched rank above watched items. 2. Among unwatched, sort by `popularity_score` descending. 3. Among watched, sort by `last_watched_timestamp` descending (most recently watched first). ```python from typing import List, Dict def get_homepage(items: List[Dict], watch_history: List[str], k: int) -> List[Dict]: # items: [{"id": str, "title": str, "popularity_score": float}] # watch_history: list of watched item ids # return: top k items as list of dicts pass ``` **Example:** ``` items = [ {"id": "A", "title": "Alpha", "popularity_score": 9.1}, {"id": "B", "title": "Beta", "popularity_score": 8.5}, {"id": "C", "title": "Gamma", "popularity_score": 7.0}, ] watch_history = ["B"] k = 2 Output: [{"id": "A", ...}, {"id": "C", ...}] # A and C are unwatched; B is excluded from top-2 slots. ``` ## Follow-ups 1. How would you incorporate a "freshness" decay so older content loses score over time? 2. What data structure best supports real-time score updates as popularity changes? 3. How would you A/B test two ranking algorithms while keeping the experiment statistically valid? 4. If the user has no watch history, how do you cold-start the ranking?
## Problem Track request latencies and support queries like percentile (p50, p99) or moving average. Likely involves heap or sorted structure for percentile computation. ## Likely LeetCode equivalent No direct match. ## Tags heap, design, coding
## Problem Compute total or average processing time for a set of tasks or requests, possibly with overlapping intervals or priority queues. ## Likely LeetCode equivalent No direct match. ## Tags heap, arrays, coding
What to Expect in the Netflix Phone Screen Round
The Netflix Software Engineer Phone Screen round has a specific calibration purpose distinct from other rounds in the loop. Across 29+ verified reports on LeakCode for this exact round type, the consistent expectations: clear scoping of the problem before diving into a solution, explicit reasoning about complexity, structured handling of edge cases, and the ability to discuss trade-offs between two reasonable approaches.
Reports tagged with the Phone Screen round at Netflix show recurring patterns in difficulty and topic distribution. The Phone Screen round is typically 45-60 minutes; the interviewer is calibrated against a specific rubric. The discriminator between candidates who advance and candidates who do not is rarely the final correctness of the answer. It is the path: did you clarify, did you verbalize your approach, did you handle edge cases, and did you communicate throughout.
How To Prepare for This Specific Round
Filter the questions below to the most recent reports (past 6-12 months). Questions tagged for this exact round type from this exact company at this exact role level are the highest-signal data available. Older reports may reference questions that have since rotated out of the company's pool.
Practice 4-6 representative problems from this set under timed conditions. The goal is not memorization (companies rotate questions); the goal is to internalize the patterns the interviewer typically reaches for and the depth of follow-up to expect. Reports on LeakCode also tag the typical follow-up depth at this round type, which is the discriminating signal between hire and no-hire calibration.
Phone Screen Round Timing and Format
The Phone Screen round at Netflix typically runs 45-60 minutes. Use the first 2-3 minutes to clarify requirements; you should never start coding or designing without verifying the input/output format, constraints, and edge cases out loud. Use the next 5-7 minutes to verbalize your approach before writing any code. The middle 20-30 minutes are implementation. Reserve the final 10 minutes for testing with concrete examples and discussing optimization or trade-offs.
Time budget discipline is one of the most reliable senior-vs-junior discriminators in this round. Strong candidates verbalize where they are in their budget out loud ("I've used about 20 minutes, I have 15 minutes left for testing and one optimization"). This signals engineering maturity to the interviewer and creates positive feedback they can capture in writing.
Common Failure Modes in This Round
Reports tagged "no hire" at Netflix Software Engineer Phone Screen commonly cite: coding silently without verbalizing approach, jumping to implementation before clarifying requirements, missing edge cases (empty input, single element, very large input), producing working code that the candidate cannot refactor when asked, and failing to test their solution with concrete examples before declaring done.
The single most predictive failure mode in 2025-2026 reports: not asking clarifying questions. Interviewers at all FAANG companies are explicitly trained to weight this dimension. Strong candidates ask 3-5 clarifying questions even on problems that look obvious; weak candidates dive into code immediately. The clarifying-question check is often the first signal recorded in the interviewer's notes.
See All 29 Questions from This Round
Full question text, answer context, and frequency data for subscribers.
Get Access